4.注册文件系统
前面说了,在安装一个文件系统的时候,需要为“被安装设备”创建一个 super_block,并设置它。
如果从源码追寻这个创建和设置 super_block 的过程,就引出了“注册文件系统”的概念。
实际上,在安装一个文件系统之前,还需要有一个注册文件系统的步骤,否则内核就因为不认识该文件系统而无法完成安装。
通过register_filesystem() ,将一个“文件系统类型”结构 file_system_type注册到内核中一个全局的链表file_systems 上。
struct file_system_type {
const char *name;
int fs_flags;
struct super_block *(*read_super) (struct super_block *, void *, int);
struct module *owner;
struct file_system_type * next;
struct list_head fs_supers;
};
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
if (!fs)
return -EINVAL;
if (fs->next)
return -EBUSY;
INIT_LIST_HEAD(&fs->fs_supers);
write_lock(&file_systems_lock);
p = find_filesystem(fs->name);
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
这个结构中最关键的就是 read_super() 这个函数指针,它就是用于创建并设置 super_block 的目的的。
因为安装一个文件系统的关键一步就是要为“被安装设备”创建和设置一个 super_block,而不同的具体的文件系统的 super_block 有自己特定的信息,因此要求具体的文件系统首先向内核注册,并提供 read_super() 的实现。
5.根据路径名寻找目标节点的 dentry
下面来研究文件系统中的一个非常关键的操作:根据路径名寻找目标节点的 dentry。
例如要打开 /mnt/win/dir1/abc 这个文件,就是根据这个路径,找到目标节点 ‘abc’ 对应的 dentry ,进而得到 inode 的过程。
5.1.寻找过程
寻找过程大致如下:
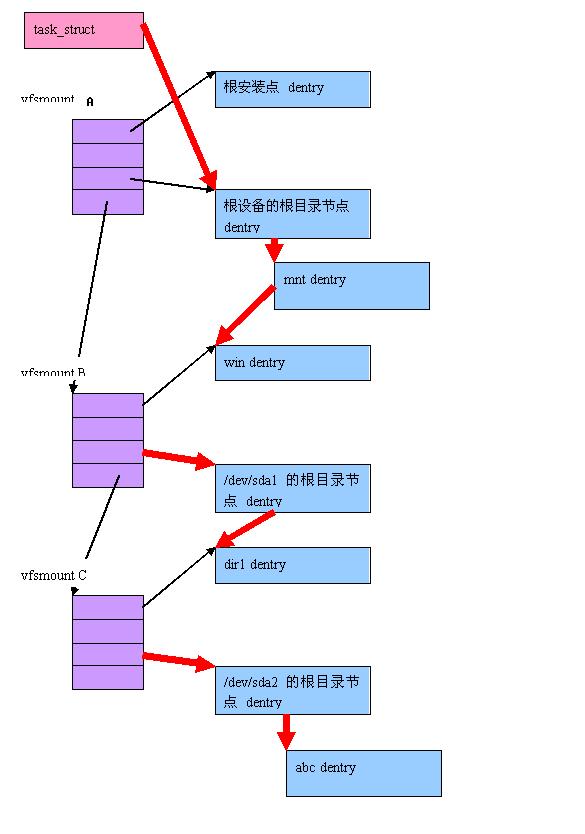
- 首先找到根文件系统的根目录节点 dentry 和 inode
- 由这个 inode 提供的操作接口 i_op->lookup(),找到下一层节点 ‘mnt’ 的 dentry 和 inode
- 由 ‘mnt’ 的 inode 找到 ‘win’ 的 dentry 和 inode
- 由于 ‘win’ 是个“安装点”,因此需要找到“被安装设备”/dev/sda1 根目录节点的 dentry 和 inode,只要找到 vfsmount B,就可以完成这个任务。
- 然后由 /dev/sda1 根目录节点的 inode 负责找到下一层节点 ‘dir1’ 的 dentry 和 inode
- 由于 dir1 是个“安装点”,因此需要借助 vfsmount C 找到 /dev/sda2 的根目录节点 dentry 和 inode
- 最后由这个 inode 负责找到 ‘abc’ 的 dentry 和 inode
可以看到,整个寻找过程是一个递归的过程。
完成寻找后,内存中结构如下,其中红色线条是寻找目标节点的路径
现在有两个问题:
- 在寻找过程的第一步,如何得到“根文件系统”的根目录节点的 dentry?
答案是这个 dentry 是被保存在进程的 task_struct 中的。后面分析进程与文件系统关系的时候再说这个。
- 如何寻找 vfsmount B 和 C?
这是接下来要分析的。
5.2.vfsmount 之间的关系
我们知道, vfsmount A、B、C 之间形成了一种父子关系,为什么不根据 A 来找到 B ,根据 B 找到 C 了?
这是因为一个文件系统可能同时被安装到不同的“安装点”上。
假设把 /dev/sda1 同时安装到 /mnt/win 和 /mnt/linux 下
现在 /mnt/win/dir1 和 /mnt/linux/dir1 对应的是同一个 dentry!!!
然后,又把 /dev/sda2 分别安装到 /mnt/win/dir1 和 /mnt/linux/dir1 下
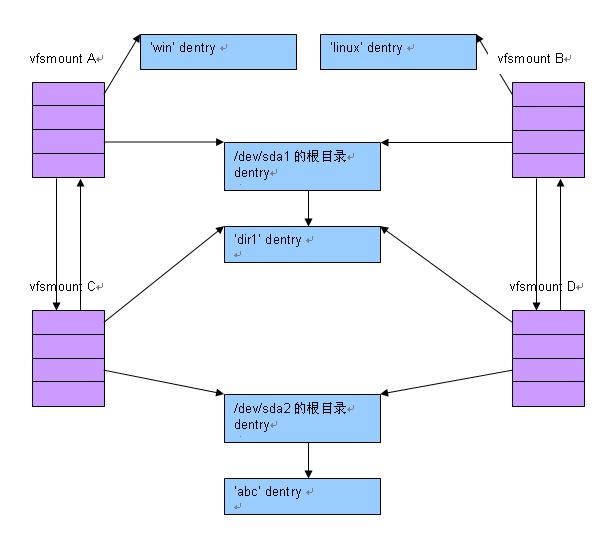
现在, vfsmount 与 dentry 之间的关系大致如下。可以看到:
- 现在有四个 vfsmount A, B, C, D
- A 和B对应着不同的安装点 ‘win’ 和 ‘linux’,但是都指向 /dev/sda1 根目录的 dentry
- C 和D 对应着这相同的安装点 ‘dir1’,也都指向 /dev/sda2 根目录的 dentry
- C 是 A 的 child, A是 C 的 parent
- D 是 B 的 child, B 是 D 的 parent
5.3.搜索辅助结构 nameidata
在递归寻找目标节点的过程中,需要借助一个搜索辅助结构 nameidata,这是一个临时结构,仅仅用在寻找目标节点的过程中。
在搜索初始化时,创建 nameidata,其中 mnt 指向 current->fs->rootmnt,dentry 指向 current->fs->root
dentry 随着目录节点的深入而不断变化;
而 mnt 则在每进入一个新的文件系统后发生变化
以寻找 /mnt/win/dir1/abc 为例
开始的时候, mnt 指向 vfsmount A,dentry 指向根设备的根目录
随后,dentry先后指向 ‘mnt’ 和 ‘win’ 对应的 dentry
然后当寻找到 vfsmount B 后,mnt 指向了它,而 dentry 则指向了 /dev/sda1 根目录的 dentry
有了这个结构,上一节的问题就可以得到解决了:
在寻找 /mnt/win/dir1/abc 的过程中,首先找到 A,接下来在要决定选 C 还是 D,因为是从 A 搜索下来的, C 是 A 的 child,因此选择 C 而不是 D;同样,如果是寻找 /mnt/linux/dir1/abc,则会依次选择 B 和D。这就是为什么 nameidata 中要带着一个 vfsmount 的原因。
6.打开文件
6.1.“打开文件”结构 file
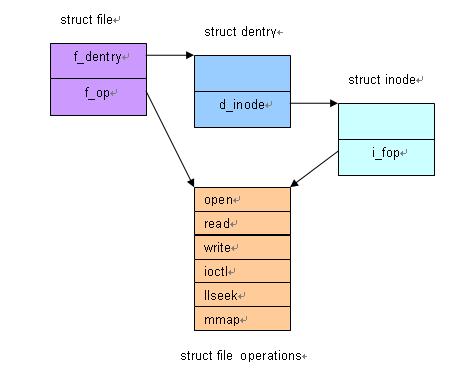
一个文件每被打开一次,就对应着一个 file 结构。
我们知道,每个文件对应着一个 dentry 和 inode,每打开一个文件,只要找到对应的 dentry 和 inode 不就可以了么?为什么还要引入这个 file 结构?
这是因为一个文件可以被同时打开多次,每次打开的方式也可以不一样。
而dentry 和 inode 只能描述一个物理的文件,无法描述“打开”这个概念。
因此有必要引入 file 结构,来描述一个“被打开的文件”。每打开一个文件,就创建一个 file 结构。
file 结构中包含以下信息:
- 打开这个文件的进程的 uid,pid
- 打开的方式
- 读写的方式
- 当前在文件中的位置
实际上,打开文件的过程正是建立file, dentry, inode 之间的关联的过程。
7.文件的读写
文件一旦被打开,数据结构之间的关系已经建立,后面对文件的读写以及其它操作都变得很简单。就是根据 fd 找到 file 结构,然后找到 dentry 和 inode,最后通过 inode->i_fop 中对应的函数进行具体的读写等操作即可。
8.进程与文件系统的关联
8.1. “打开文件”表和 files_struct结构
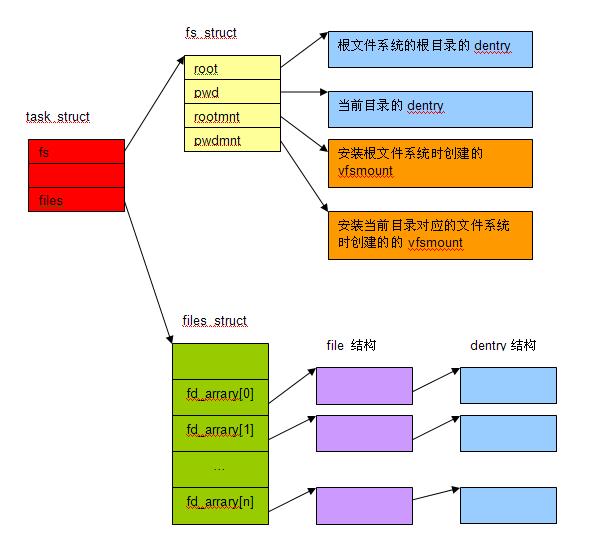
一个进程可以打开多个文件,每打开一个文件,创建一个 file 结构。所有的 file 结构的指针保存在一个数组中。而文件描述符正是这个数组的下标。
我记得以前刚开始学习编程的时候,怎么都无法理解这个“文件描述符”的概念。现在从内核的角度去看,就很容易明白“文件描述符”是怎么回事了。用户仅仅看到一个“整数”,实际底层对应着的是 file, dentry, inode 等复杂的数据结构。
files_struct 用于管理这个“打开文件”表。
struct files_struct {
atomic_t count;
rwlock_t file_lock;/* Protects all the below members.Nests inside tsk->alloc_lock */
int max_fds;
int max_fdset;
int next_fd;
struct file ** fd;/* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
fd_set close_on_exec_init;
fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};
其中的 fd_arrar[] 就是“打开文件”表。
task_struct 中通过成员 files 与 files_struct 关联起来。
8.2. structfs_struct
task_struct 中与文件系统相关的还有另外一个成员 fs,它指向一个 fs_struct 。
struct fs_struct {
atomic_t count;
rwlock_t lock;
int umask;
struct dentry * root, * pwd, * altroot;
struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
};
其中:
- root 指向此进程的“根目录”,通常就是“根文件系统”的根目录 dentry
- pwd 指向此进程当前所在目录的 dentry
因此,通过 task_struct->fs->root,就可以找到“根文件系统”的根目录 dentry,这就回答了 5.1 小节的第一个问题。
- rootmnt :指向“安装”根文件系统时创建的那个 vfsmount
- pwdmnt:指向“安装”当前工作目录所在文件系统时创建的那个 vfsmount
这两个域用于初始化 nameidata 结构。
8.3.进程与文件系统的结构关系图
下图描述了进程与文件系统之间的结构关系图:
9.参考资料
1、《Linux 源码情景分析》上册
2、Linux 2.4.30 源码
struct nameidata {
struct dentry *dentry;
struct vfsmount *mnt;
struct qstr last;
unsigned int flags;
int last_type;
};
static inline struct inode *iget(struct super_block *sb, unsigned long ino)
{
struct inode *inode = iget4_locked(sb, ino, NULL, NULL);
if (inode && (inode->i_state & I_NEW)) {
sb->s_op->read_inode(inode);
unlock_new_inode(inode);
}
return inode;
}
-
 热敏电阻温度阻值查询程序2024年11月13日 74
热敏电阻温度阻值查询程序2024年11月13日 74 -
C99语法规则2024年11月16日 675
-
 FreeRTOS 动态内存管理2024年11月12日 448
FreeRTOS 动态内存管理2024年11月12日 448 -
一款常用buffer程序2024年11月06日 88
-
 1602液晶显示模块的应用2012年08月03日 192
1602液晶显示模块的应用2012年08月03日 192 -
GNU C 9条扩展语法2024年11月18日 261
-
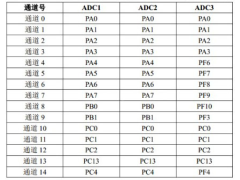 如何实现STM32F407单片机的ADC转换2024年11月15日 300
如何实现STM32F407单片机的ADC转换2024年11月15日 300 -
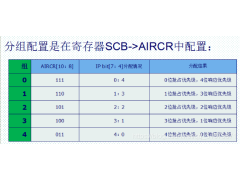 STM32使用中断屏蔽寄存器BASEPRI保护临界段2024年11月15日 195
STM32使用中断屏蔽寄存器BASEPRI保护临界段2024年11月15日 195
-
C99语法规则2024年11月16日 675
-
 51单片机LED16*16点阵滚动显示2012年09月05日 664
51单片机LED16*16点阵滚动显示2012年09月05日 664 -
FreeRTOS 动态内存管理2024年11月12日 448
-
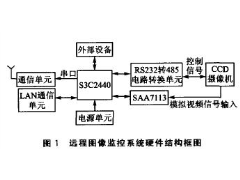 ARM9远程图像无线监控系统2012年07月03日 424
ARM9远程图像无线监控系统2012年07月03日 424 -
 用单片机模拟2272软件解码2012年09月06日 300
用单片机模拟2272软件解码2012年09月06日 300 -
如何实现STM32F407单片机的ADC转换2024年11月15日 300
-
 新颖的单片机LED钟2012年08月06日 278
新颖的单片机LED钟2012年08月06日 278 -
GNU C 9条扩展语法2024年11月18日 261